Where do you live and what do you do? –Why, does it matter?
Many organizations keep multiple data models, each one specialized for a specific use. These models are hardly maintained in harmony. This situation is unwanted: it results in a large number of overlapping but inconsistent models, while maintenance of these models is costly. This posting is intended to put forward a CDM as a possible solution to this problem. At least, it makes a start.
Where do you live and what do you do? –Why, does it matter?
Data live in many different houses. It’s where we put them: in external memories (in database tables or in data files) for data storage and retrieval, in message fields for data exchange, in user interface windows and on paper printouts for data presentation to human users, in microprocessor registers for direct data processing and in internal memory structures for indirect data processing. And I don’t pretend to be exhaustive here.
So, we can do many different things with data, and as a consequence of that, we put them in different places. For anything we can do with our data, one place is more suitable than another. Processing data directly from a hard drive? Better not. Storing data in internal memory? Risky. And automated systems read data from a piece of paper reliably and efficiently only with a lot of effort.
What’s the constant factor in this story? It’s the data themselves. Whatever we intend to do with them, wherever we put them, they still remain the same data. At least, their semantics remain the same. It’s only after some processing has been carried out on the data, that we can expect a change in semantics in the results.
There are, however, some aspects to our data that may very well be adapted to what we want to do with them or to where we want to put them. These aspects have nothing to do with data semantics. Instead, they are the citizens of the technical data model, describing the technical formats of the data. Data oftentimes take on a different format when moving to another house, just like you would put on a jacket when leaving home for work.
So where is all this leading to? Well, this story contributed to the global design of our world of canonical data modeling. We make an explicit distinction between semantics and technical formats. We use different model types for them. Semantics are described in a conceptual model, whereas descriptions of technical formats can be found in a technical model. Because of the fact that we model data living in a large number of houses, even houses of different types, we create multiple technical models.
But what about our conceptual models? Well, there is only one. For the data we want to describe, it doesn’t matter where they are, or what we intend to do with them. This one conceptual model supports many of our Applications of a CDM. For example, it eases correct data mapping (see app 2), and it gives a practical data catalogue to search for data living anywhere (see app 3).
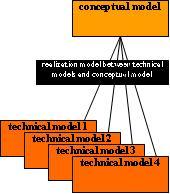
Oh yes, there’s a third type of model involved, one that relates the semantics to the technical formats. It describes the relationships between the elements in the technical models and the elements in the conceptual model.
Your data systems, whether it be a business application, a database, a data warehouse, a message type or whatever thing that your data can live in, should all have their own technical data model, all linked to your one-and-only CDM! This will help reducing cost and it will give your data models more value.
posted by Maarten @ 10:16
1 comments
![]()
![]()

1 Comments:
Nou Maarten, ik heb me er toe kunnen zetten om het boek ‘Data and Reality’ van William Kent te lezen. In de kerstvakantie. Geen ‘licht leesvoer’ om het zomaar eens uit te drukken. Foei!
Het begon goed en ik begreep wat hij schreef tot halverwege H 2. Vanaf H 3 tot en met paragraaf 7.1 was ik het kwijt. Dingen, relaties die ook dingen zijn, het verschil tussen types en soorten. Lastig hoor!
In par. 7.2 komen we aan het conceptueel model. De poging om de realiteit in een conceptueel model te vatten en niet proberen te wringen in een database. Dat las goed en begreep ik wel.
Toen gingen we over tot het terugbrengen van alles (objecten) in tot 1 op 1 relaties en toen zag ik ook weer de ouderwetse ERD's verschijnen die ik ooit eens moest kennen vanwege een Ambimodule SQL. Ik dacht: “dan ben je toch weer terug bij af?”
Ik was totaal in verwarring. Misschien helpt het ook niet mee dat het allemaal in het Engels is. Dat is voor mij soms een extra hobbel om dingen echt goed te doorgronden. Het is immers mijn moers taal niet.
Verder vond ik het een en al chagrijn. In ieder geval tot hoofdstuk 12. Toen begon er wat licht aan de horizon te schijnen.
Met wat naslagwerk op het Internet zag ik ook dat dhr. Kent later tot de club van OGM is toegetreden die het UML hebben samengesteld.
Enfin.
Kent toont min of meer aan dat principiele verandering nodig is en standaardisatie. Ik vraag mij af of zo de betekenisordeningen als dwangbuizen gezien moeten worden.Zo voelt het wel een beetje. Maar meerduidigheid ljkt in een informatiemodel verboden te moeten worden.
FWIW.
Mary
Post a Comment
<< Home