In earlier blog postings, I’ve argued that in order to enable powerful appliances for a canonical data model, it will have to contain semantic data descriptions next to the mere technical formatting descriptions that can be found in almost any data model. This idea has yet to become commonplace. One cause for our reluctance to incorporate semantic descriptions probably is the big melting pot of buzz words that seems to inevitably have to accompany each new idea in IT (SOA is another one!). The idea of a CDM comes with its own pot, of course, thereby creating a lot of confusion. This posting is meant to give some essential terms a place, hopefully increasing people’s understanding of the world of the CDM.
Data Formats, Semantics and Meanings in a CDMThis one melting pot contains, among others, such terms as
data semantics,
data meaning and
data format. What’s their significance, and how should they be applied?
One important notion is, that data have a whole lot of characteristics. Therefore, you can find a number of different types of data models, each providing you with its own set of
metadata, data describing your business data. You can, for example, think of the data’s
data types, their
field lengths (sounds familiar this far?) and their
semantics, their
owners and
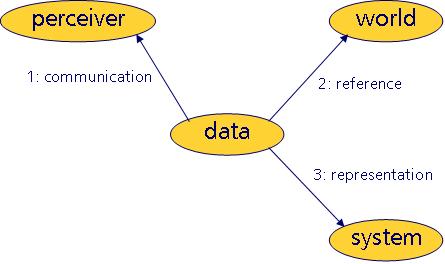
users, etcetera. A simple organizing model that you might find useful is the one below.

From this little model, it can be read that data
1. are communicated to perceivers
2. refer to things in a ‘world’
3. are represented (stored and/or presented) in information systems
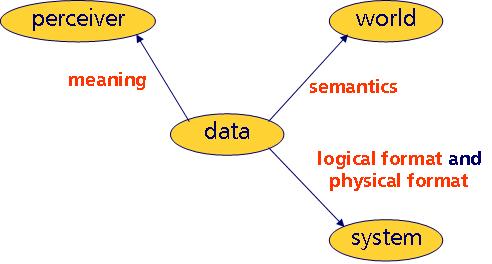
These three aspects are fundamental to any type of data or data use. This view can shed light on the way our terms can be used best. For instance, each fundamental can be associated with one of our three buzz words. Here’s the same picture, now with the buzz words filled in.
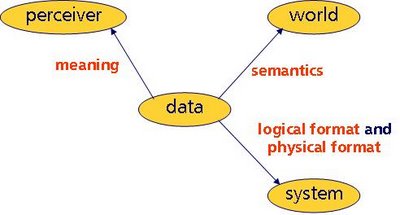
So, according to this model, the perception of data is linked to data
meaning, the data’s reference to a world is associated with data
semantics, and data representations have something to do with data
formatting. Let’s delve a little deeper into the nature of these associations.
Technical FormattingThis probably is the only aspect of data that most of us are familiar with. It results from the fact that data only ‘exist’ in our world if they are represented somewhere physically, in a computer system’s memory, on a piece of paper, in a brain or in whatever thing that can hold or represent data. In this light it’s not surprising that almost all data models we have are directed to this aspect of the data, giving insight to their data types, data masks, units of measurement, and the like.
Technical formatting can be divided into two parts: one to describe those data structure characteristics that are independent from the physical systems that actually represent or hold the data, and one that covers physical implementations in specific physical systems. All abovementioned formatting attributes are of the system-independent type. Examples of physical implementation attributes are endianism and byte word length.
It’s important to realize that formatting has no impact whatsoever on semantics. A specific semantics can be realized technically in a vast number of ways. As an example, metrical objects (a matter of semantics) can be realized using numerical data types, but also by applying non-numerical types like strings.
SemanticsIt’s too bad that, unlike data formatting, data semantics are so invisible and intangible to us, because this is really what data are all about. Data semantics constitute a world of concepts (ideas, which we cannot see), rather than of symbols.
Symbol juggling is probably due to this invisibility, giving rise to a number of problems related to the way we treat our data.
At this point, it’s important to have a good understanding of what data actually are. As you can make up from the
symbol juggling posting, they are not the symbols that we see on our computer screens, for instance. Let’s define data as being statements about objects in a ‘world’, whether true or false. This ‘world’ can be either real or imaginative. The objects are whatever ‘things’ that are relevant to an intelligent actor in, or perceiver of that world. So, data always describe small parts of situations in that world. Data semantics, then, should be conceived of as the content of these statements, that what is being stated about that object in that world. This is the reference-to-things-in-a-world aspect of data.
MeaningJust like data semantics, meaning in itself is invisible. Meaning is, in my view, defined roughly as ‘the consequence of the perception of an event’. Although I use this definition in a broader, more philosophical sense, in this discussion it’s restricted to the world of psychology: When you perceive an event that happens, you extract information (data) from it in the form of semantics, among other things like tone of voice or timing. Then, on the basis of all information extracted, your brain starts to construct meaning by activating inference processes. This meaning you construct is what the event means to you, now. Hence, meaning is extremely depending on the availability and accessibility of knowledge in an intelligent object (not necessarily a human being!) at a very specific moment in time. It’s clear that meaning understood in this way cannot be modeled formally, not even in the most sophisticated CDM we can think of. Still, this concept is relevant in the domain of the CDM, partly because it plays a role in communication processes. Next to that, it can be used to make clear that this is NOT what we’re trying to model in our CDM.
ConclusionsNow, to conclude, data formatting is what you describe in a technical data model (logical and maybe also physical, if need be), data semantics is what you clarify in a semantical (or ‘conceptual’) data model, and data meaning is what I hope you’ll never try to formalize in any kind of data model, but what you should keep in mind in order to create really effective communication processes. Although effective communication strongly leans on shared data semantics, it really is much more than that, resulting from the fact that its effectiveness is not so much measured in terms of a mutual
understanding of the things stated as it is in terms of its
effect on the listener being in accord with the speaker's intention. Communication is, after all, a means for an actor to indirectly create an effect in a perceiver.
By the way, for our CDM we’re using the model types briefly described in
this posting.